Classification in Machine Learning: A Brief Introduction
Table of Contents
Today, industries use classification algorithms in machine learning for a variety of applications. For instance, it is used in spam filtering, medical diagnosis, image classification, image sentiment analysis, credit card fraud detection, customer behavior prediction and the list goes on…
In other words, it is one of the most commonly encountered problems in real-world scenarios, that involves the categorization of input data in predefined classes. Further, specific classification algorithms called classifiers, solve these problems based on different requirements.
With this blog, I would like to introduce you to –
the basic concept of classification in machine learning and how it works
different types of classification problems (along with commonly used algorithms)
how are they different from regression and clustering problems
But, if you are new to machine Learning and want to cover the basics first, you can take a quick read to my other blog here. If you are already familiar with the basics, then let’s dive into it !!
What is Classification??
” Classification in Machine Learning is a type of problem where the model has to predict a class label for a given input sample.”
This input sample could be an image, text, sound, or any other type of data.
Example
To understand the concept, let us take a simple 1-D problem.
Let us say, I get some ratings from the readers for this blog. These ratings range from 0 to 5. Now for my analysis, I want to categorize them into two classes – positive 🙂 and negative 🙁 ratings. But, I don’t know which ratings should be positive and which ones should be negative. So, I need a trained classification model that can perform this task for me.
But before that, the classes need to be assigned number labels , 1 (for positive) and 0 (for negative). This allows the model to predict a quantity that maps to respective class labels.
Now, since the classification problem is a Supervised Learning technique, we need labeled examples to train the model. Therefore, I use already labeled ratings from similar blogs on the internet as my training dataset. This trained model is the best-fitting function on the input data, which can be calculated in a way similar to that of Regression problems
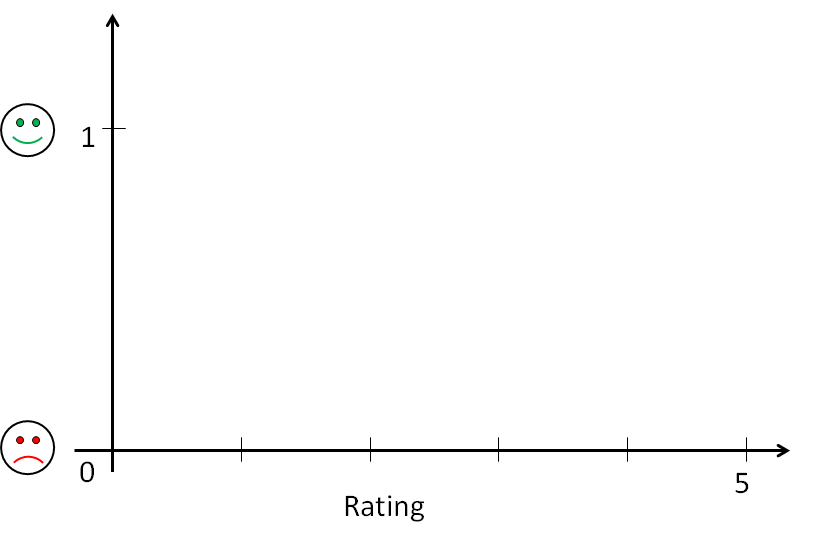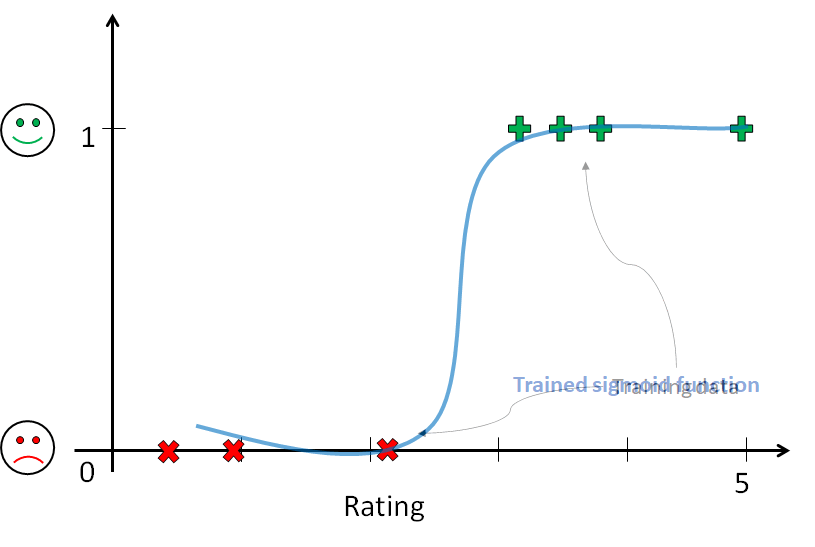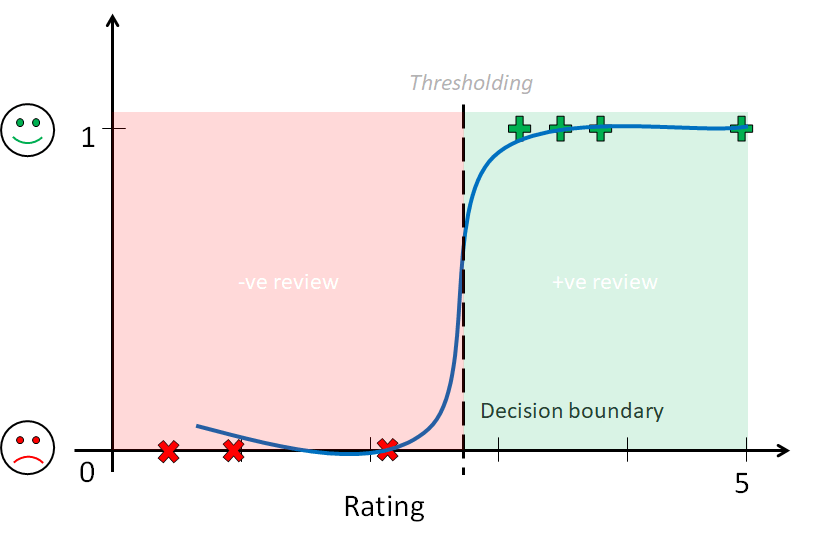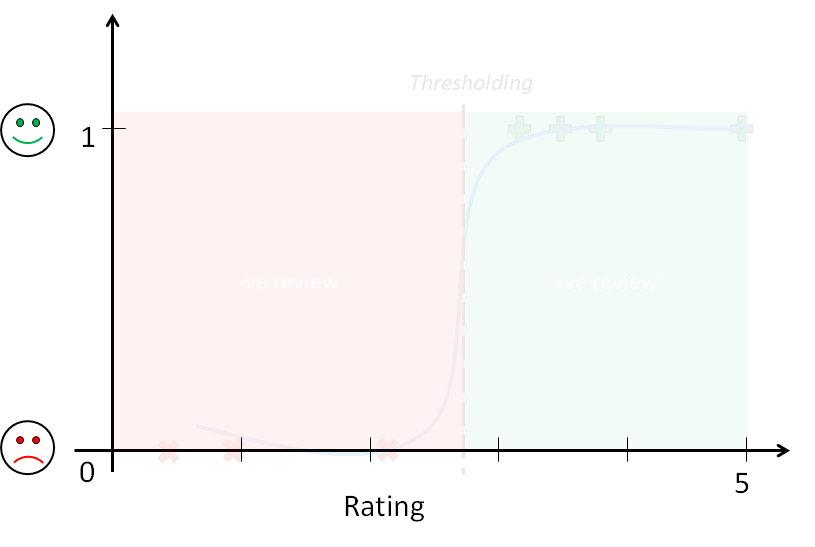
But unlike regression problems, these functions must map input values to probabilities for predicted class labels and hence must predict values only between 0 and 1. So, we use sigmoid functions as our models.
Once the model is trained based on training data, there is an additional step of thresholding the function values to get class labels. The boundary or threshold where the class labels change their value is the decisionboundary of the classification model.
“The decision boundary is the fundamental aspect of classification problems. It is the set of points where the data has equal probability to be classified in any predefined class”
In other words, the decision boundary decides the separation between the classes. Once the decision boundary is known, our classification model is ready to predict classes for unseen input data points.
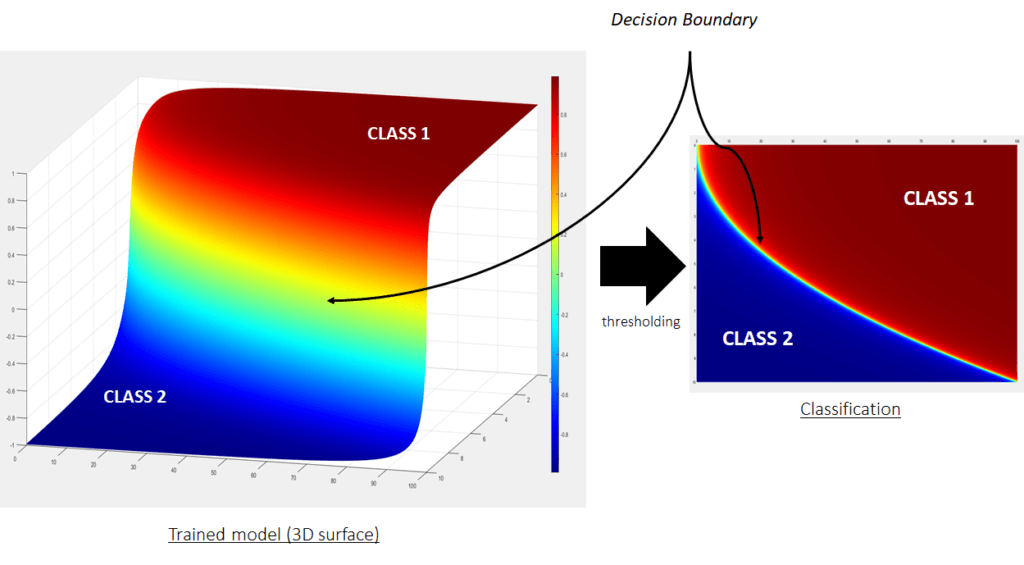
To sum up, the above example briefly introduced the concept of classification models in 1-D space (rating scale). Similarly, for higher dimensional problems, functions in original space are fitted to the training data. Then, decision boundaries are derived from the trained functions using thresholding. This decision boundary is always in dimension one less than that of original space.
For instance, in the case of 2-D problems, the decision boundary line (1-D function) is derived from a 2-D trained function (as shown below)
To read more on the decision boundaries, refer to the other blog here
Types of Classification
Now, there are variety of classification problems in real world. For simplification, those are divided into three main categories –
Binary classification
Multi-class classification
Multi-label classification
Binary Classification
In these type of problems, there are only two predefined classes for the input dataset.
Moreover, the classes here are labeled in binary format. It could be “true or false”, “spam or not spam”, “positive or negative” and so on, depending on the type of problem.
Commonly used algorithms :
Logistic Regression
Support Vector Machines (SVMs)
Multi-Class Classification
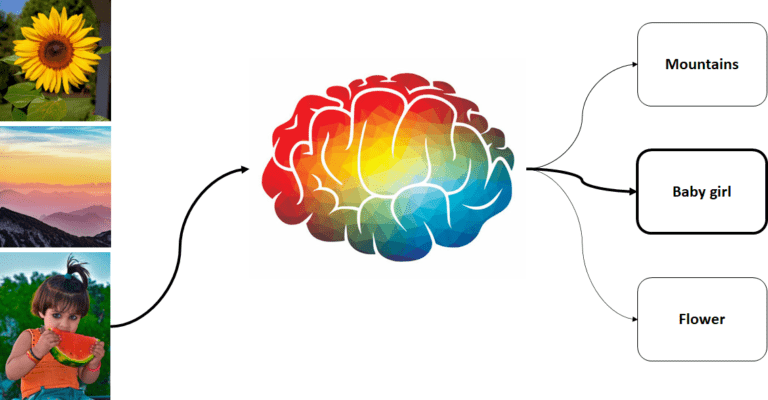
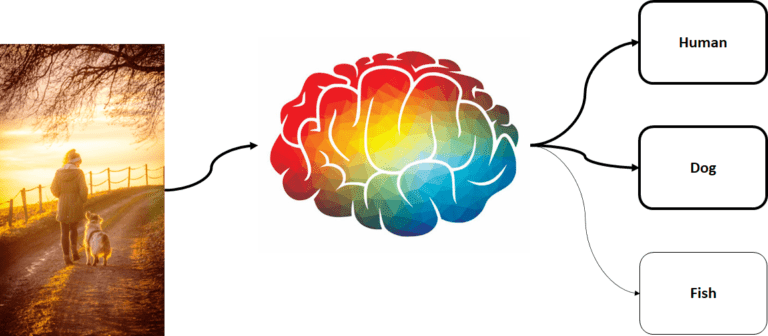
When we have more than two predefined classes for the input dataset, it is called multi-class classification. For instance, we can have classes representing different types of subjects in input images. Here, the trained classification model assigns respective labels to the subject in the image.
Commonly used algorithms :
Random Forest
K-nearest neighbours
Naive Bayes
Logistic Regression
Support Vector Machines (SVMs)
Multi-Label Classification
In these types of problems, there can be more than one class label for “each input sample”.
In other words, instead of assigning just one label to a sample, the classification task can assign a group of labels to any sample. These cases occur for example when an image contains more than one subject and hence the image can be labeled to multiple class labels. These types of problems have specialized classification algorithms.
Commonly used algorithms :
Multi-label decision trees
Multi-label gradient boosting
Multi-label random forests
Now, since we know the basic concept and different types of classification problems, we are equipped to compare the classification models with other similar models.
Classification vs. Regression
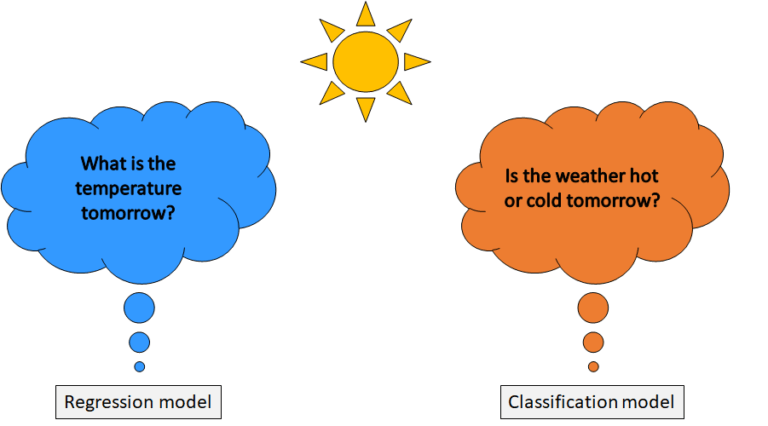
Classification and regression, both are part of supervised machine learning techniques that use labelled datasets to train the model. However, the main difference lies in the nature of the output values that they predict.
“Classification predicts categorical values, while regression predicts continuous values”
To read step-by-step implementation of regression models, refer to this blog, where all the steps are explained with a clear example.
Classification vs. Clustering
It is often confusing because both classification and clustering models, group the data based on some input features. But, the difference lies in the purpose for which the data is grouped together.
“Classification groups data to assign it to predefined class labels, while clustering groups the data to find similar or hidden patterns in the data.
Further, classification uses labelled dataset to train the model (supervised learning). Whereas, clustering do not require labelled dataset to find patterns in the data (unsupervised learning).
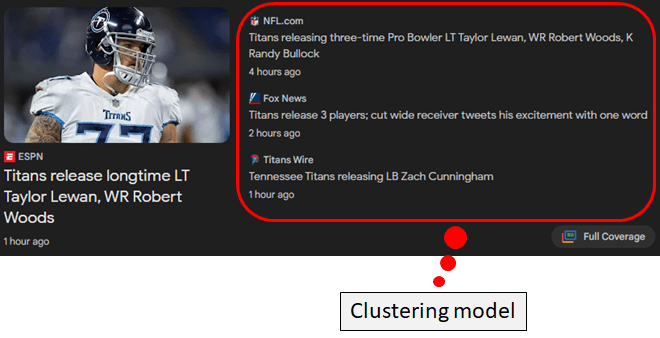
For instance, Google uses a clustering model to cluster similar news together based on the text included in the news articles. To learn more about clustering, refer here.
Summary
In conclusion, you are now familiarized with the classification models in machine learning.
After reading this blog, you know about –
the purpose of using classification models
the concept of thresholding in classification models
different types of classification problems and their respective algorithms
concept of regression and clustering problems and how they are different from classification problems.
With the increasing availability of data, the importance of classification models in machine learning will only continue to grow, making it an exciting area for research and development. This article was an effort to give a brief introduction to the topic.
Hope it has improved your understanding sufficiently to dive deeper into the topic and implement your own models.
Do you have any questions?
Ask them in the comments below and I will try my best to answer them.
Share:
One Response
I luckily stumbled upon this brilliant site earlier this week, they provide great info for members. The site owner excels at informing the community. I’m impressed and hope they continue their magnificent service.
Logistic regression is a machine learning model that helps in the classification of the data in pre-defined classes. The classification can be either binary (two-class)
Generative Adversarial Networks (GANs) are popular for their capabilities in generating fake data, including fake images or videos. But what made them so powerful? Read to know more about their architecture and training process.
In machine learning, a pipeline is a sequence of automated data processing and modeling steps that convert raw data into a refined predictive model. Read this blog to get hands-on tutorial on end-to-end development of a pipeline using Python.
ChatGPT is the single fastest growing human application in the whole history. It had around 100 million users in just 2.5 months from its launch date. What exactly is about ChatGPT that made it widely popular?

One Response
I luckily stumbled upon this brilliant site earlier this week, they provide great info for members. The site owner excels at informing the community. I’m impressed and hope they continue their magnificent service.